02/2024
Paper on "A Heterogeneous Agent Model of Mortgage Servicing: An Income-based Relief Analysis" at
AIFinSi workshop, AAAI 2024.
12/2023
Paper on "O3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models" at
FMDM workshop, NeurIPS 2023.
07/2023
Defended my PhD.
05/2023
Paper on "Heterogeneous Social Value Orientation Leads to Meaningful Diversity in Sequential Social Dilemmas" at
ALA workshop, AAMAS 2023.
05/2023
Defended my PhD.
12/2022
Presented our work "On Using Hamiltonian Monte Carlo Sampling for Reinforcement Learning" at
CDC 2022.
12/2022
Organized a
PNAS special issue symposium on "Collective Artificial Intelligence and Evolutionary Dynamics"
09/2022
Finished summer internship (Research Scientist Intern: Game Theory and Multi-agent team) at
Deepmind.
07/2022
Paper on " A Regret Minimization Approach to Multi-Agent Control" at
ICML 2022.
06/2021
Paper on "Provably Efficient Multi-Agent Reinforcement Learning with Fully Decentralized Communication" at
ACC 2022.
12/2021
Presented our work "One More Step Towards Reality: Cooperative Bandits with Imperfect Communication" at
NeurIPS 2021.
08/2021
Finished summer internship (Research Scientist Intern: FAIR labs) at
Meta AI Research.
06/2021
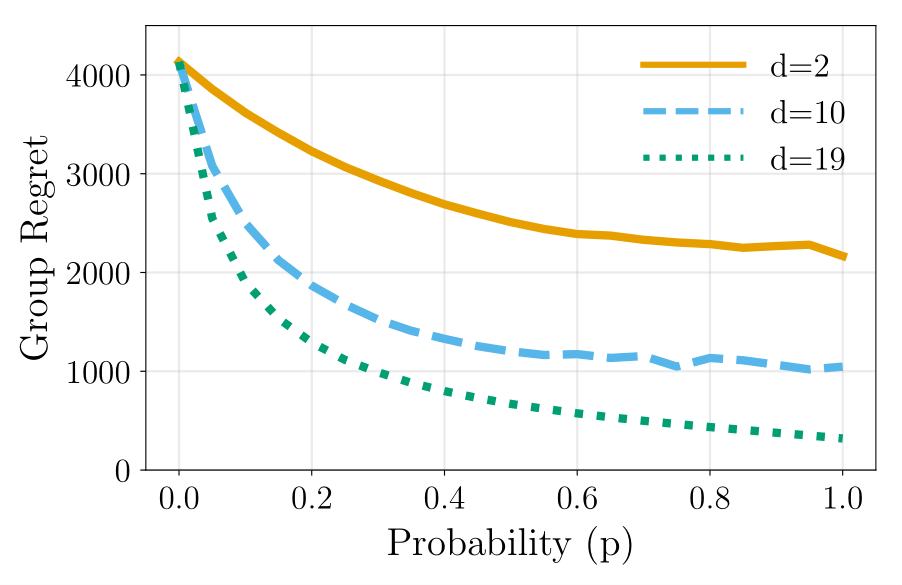
Presented our work "Distributed Bandits: Probabilistic Communication on \(d\)-regular Graphs" at
ECC 2021.
06/2021
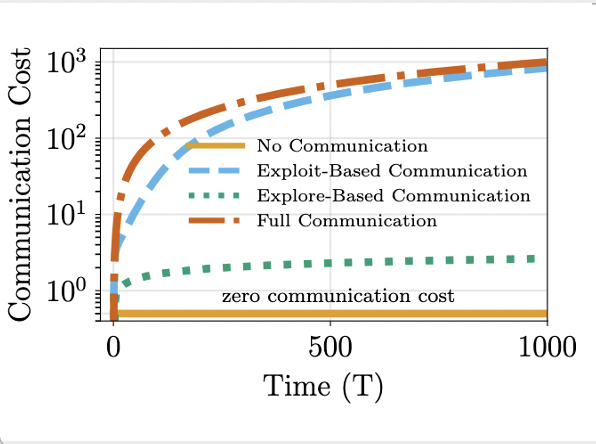
Presented our work "Cost-effective Communication Strategies for Distributed Learning Systems" at
ECC 2021.
05/2021
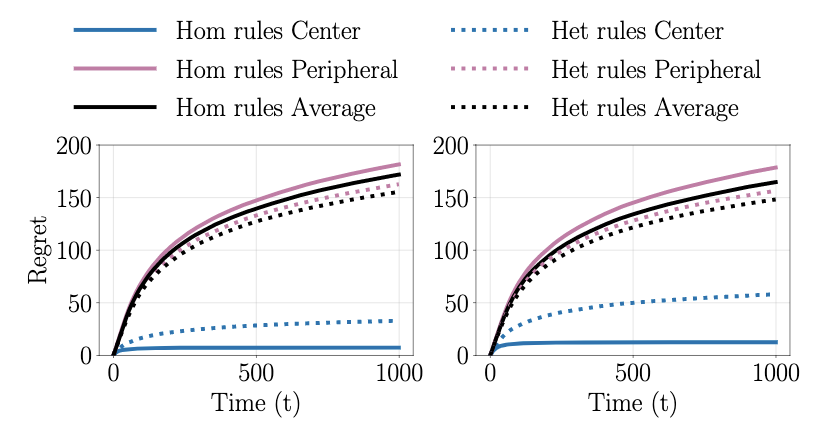
Presented our work "Heterogeneous Explore-Exploit Strategies on Multi-Star Networks" at
ACC 2021.
12/2020
Presented our work "It Doesn't Get Better and Here's Why: A Fundamental Drawback in Natural Extensions of UCB to
Multi-agent Bandits" at
ICBINB workshop, NeurIPS 2020.
11/2020
Our paper "Heterogeneous Explore-Exploit Strategies on Multi-Star Networks" got accepted to
IEEE Control Systems
Letters.
09/2020
Received Britt and Eli Harari Fellowship from the Department of
Mechanical and Aerospace Engineering, Princeton University.
08/2020
Finished summer internship (Graduate Intern: AI/Deep Learning for
Predictive Analytics) at
Siemens.
05/2020
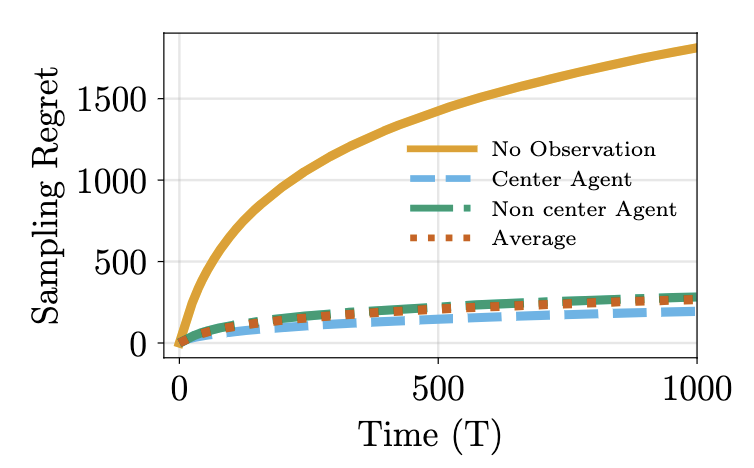
Presented our work "A Dynamic Observation Strategy for Multi-agent
Multi-armed Bandit Problem" at
ECC 2020.
04/2020
Presented our work "Distributed Learning: Sequential Decision Making in
Resource-Constrained Environments" at
PML4DC workshop, ICLR 2020.
09/2019
Received Larisse Rosentweig Klein Memorial Award from the Department of
Mechanical and Aerospace Engineering, Princeton University.
08/2019
Received a Presidential Award for Scientific Publication from the Sri
Lankan National Research Council.
06/2019
Presented our work "Heterogeneous Stochastic Interactions for Multiple
Agents in a Multi-armed Bandit Problem" at
ECC 2019.
09/2018
Received Martin Summerfield Graduate Fellowship from the Department of
Mechanical and Aerospace Engineering, Princeton University.
09/2018
Received Athena-Feron Prize from the Department of Mechanical and
Aerospace Engineering, Princeton University.
06/2018
Presented our work "Feedback Regularization and Geometric PID Control
for Robust Stabilization of a Planar Three-link Hybrid Bipedal Walking
Model" at
ACC 2018.
03/2018
Received Elliotte Robinson Little '25 Student Aid Fund Fellowship from
the School of Engineering and Applied Science, Princeton University.