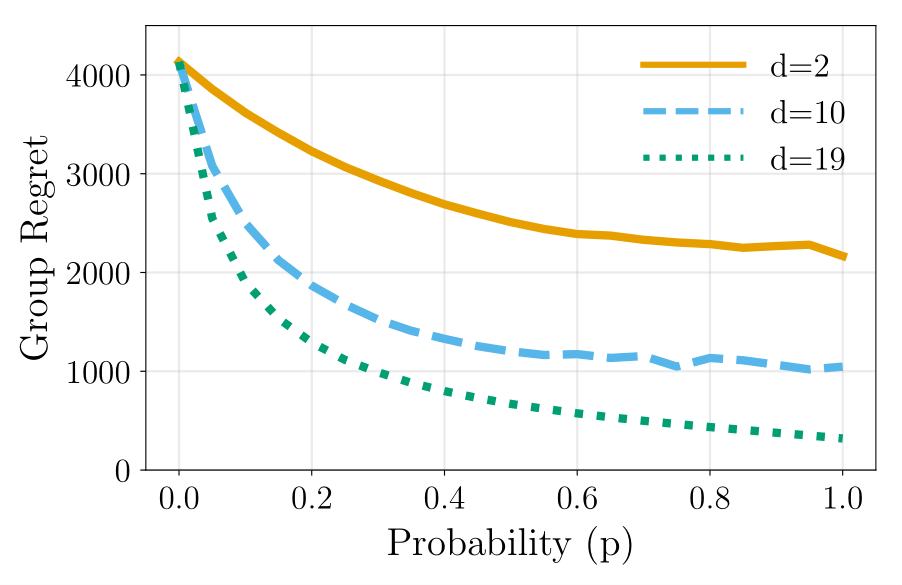
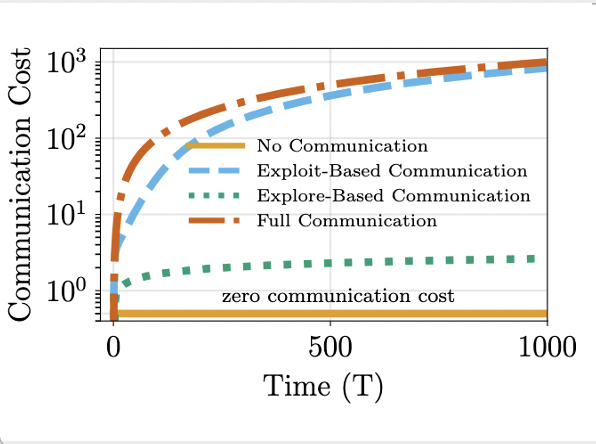
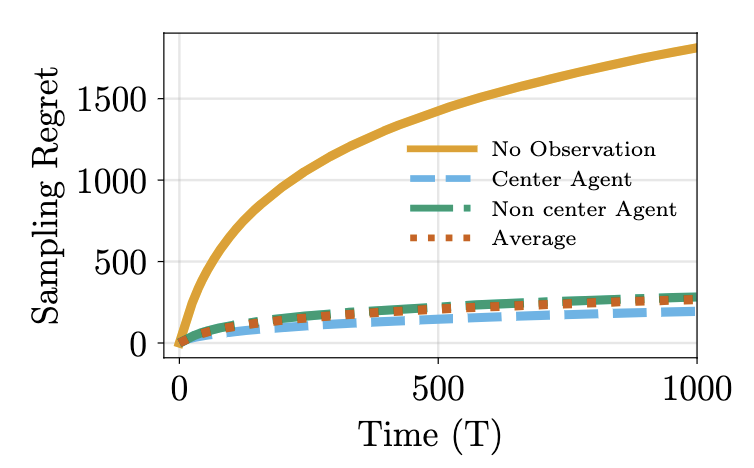
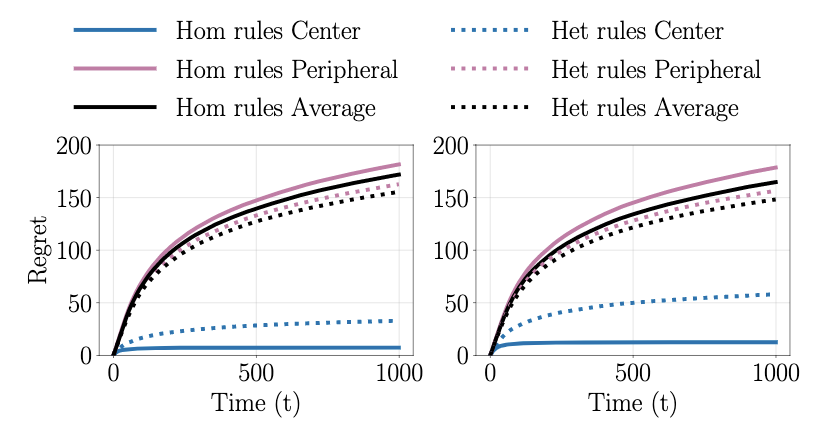
I am a research scientist at
Scale AI, SEAL team where I lead efforts on agentic AI, frontier safety and scalable oversight.
I completed my PhD at
Princeton University, where I was advised by Prof.
Naomi Leonard. I was also a visiting postdoctoral researcher at Department of Computer Science, Stanford University.
My research vision is to embed AI agents with the ability to enhance their capabilities through collective intelligence, ultimately enabling them to seamlessly coexist with humans. In my research work I primarily focus on developing capable and aligned AI agents safely and responsibly. Before joining Princeton, I completed my undergraduate at University of Peradeniya, Sri Lanka.
Research Experience
- Alignment
- Safety and Responsible AI
- Human-AI coordination
- Scalable oversight
- AI Policy and Governance
- Game Theory
- Agentic models
- Multi-agent RL
- Robotics

Visiting researcher
Stanford University
August 2023 - Present

Research scientist
JPMorgan AI Research
July 2023 - April 2025

Graduate student
Princeton University
September 2017 - May 2023

Research scientist intern
Deepmind
May 2022 - September 2022

Research scientist intern
FAIR
May 2021 - August 2021

Summer research intern
Siemens
May 2020 -
August 2020